Subiect: #LLM

Together AI și Hugging Face revoluționează antrenarea modelelor: Acum poți adapta orice LLM în doar câteva minute
Parteneriatul dintre Together AI și Hugging Face permite dezvoltatorilor să efectueze fine-tuning pe orice model LLM compatibil direct prin infrastructura cloud, eliminând complexitatea tehnică și reducând timpul de la descoperire la implementare la doar câteva minute.
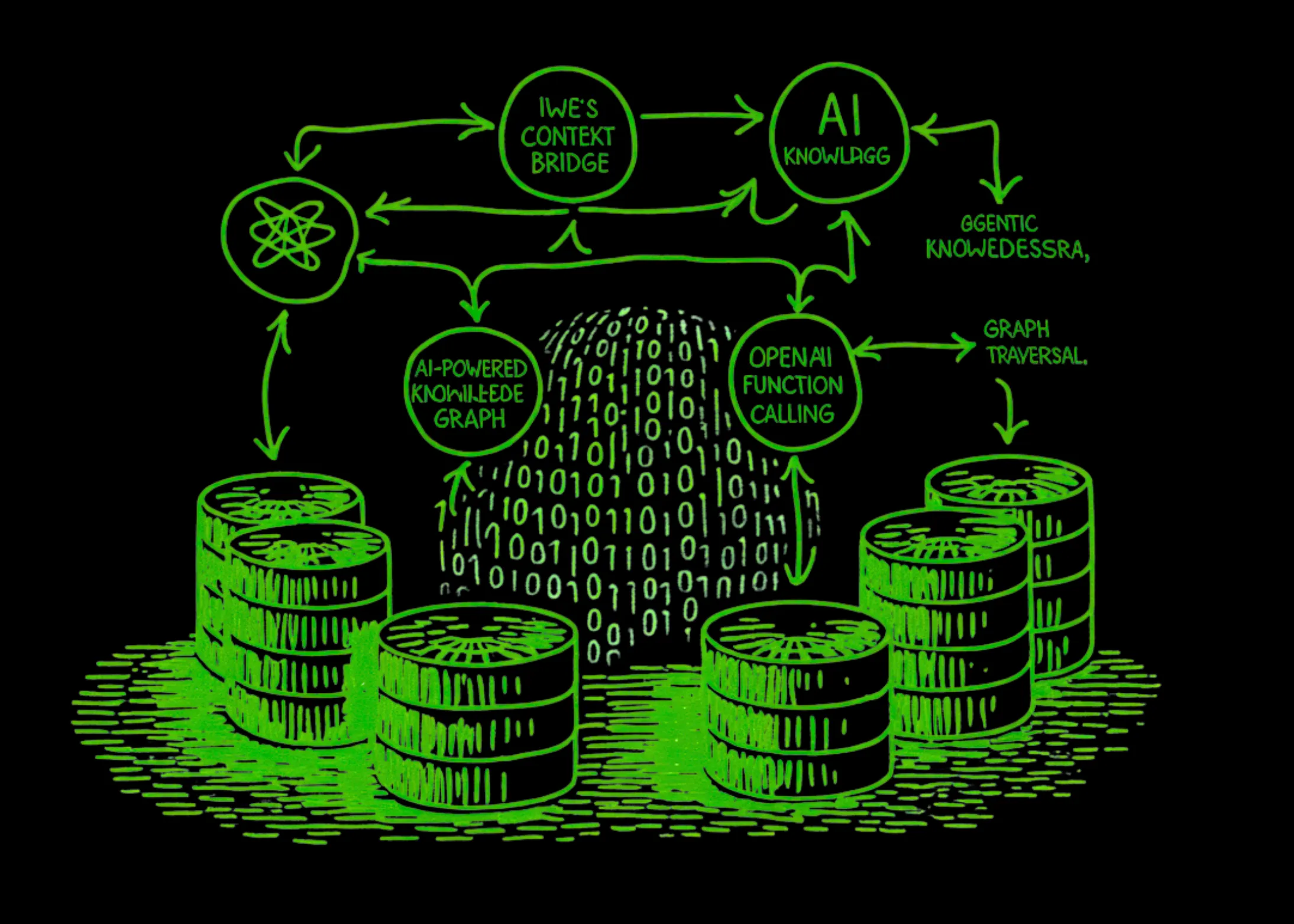
Implementarea Context Bridge de la IWE ca Graf de Cunoaștere bazat pe Inteligență Artificială, utilizând RAG Agențial, Apeluri de Funcții OpenAI și Traversare de Graf
O analiză detaliată a arhitecturii hibride propuse de IWE, care transformă datele nestructurate în Grafuri de Cunoaștere dinamice, utilizând agenți AI și RAG pentru o înțelegere contextuală superioară.
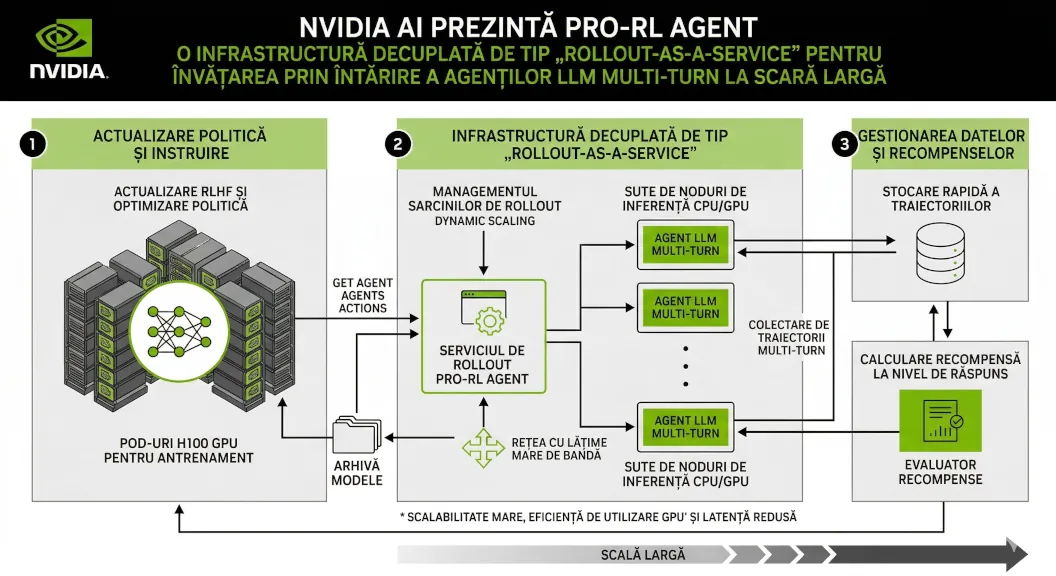
NVIDIA AI prezintă ProRL Agent: O infrastructură decuplată de tip „Rollout-as-a-Service” pentru învățarea prin întărire a agenților LLM multi-turn la scară largă
Cercetătorii de la NVIDIA au lansat ProRL Agent, o infrastructură scalabilă care revoluționează antrenarea agenților LLM prin decuplarea procesului de colectare a experiențelor (rollout) de bucla de antrenament, rezolvând astfel conflictele majore de resurse care îngreunează dezvoltarea AI-ului la scară largă.

Swift Transformers atinge versiunea 1.0 – și privește spre viitorul inteligenței artificiale pe dispozitivele Apple
Biblioteca Swift Transformers a lansat versiunea 1.0, stabilind un nou standard pentru dezvoltarea aplicațiilor AI locale pe Apple Silicon, cu un accent pe integrarea MLX și cazuri de utilizare agentică.

Nemotron-Personas-Japan: Un set de date sintetic pentru dezvoltarea Inteligenței Artificiale Suverane în Japonia
NVIDIA lansează Nemotron-Personas-Japan, primul set de date sintetic open-source dedicat culturii și demografiei japoneze, facilitând dezvoltarea AI-ului suveran și eliminând barierele de confidențialitate pentru dezvoltatorii locali.

Aliniere la Ce? Reevaluarea Generalizării Agenților în MiniMax M2
Articolul explorează provocările fundamentale în dezvoltarea agenților AI, punând în contrast performanța la benchmark-uri cu utilitatea reală. Se discută conceptul de „Gândire Intercalată” și importanța menținerii contextului complet pentru performanța optimă a modelului MiniMax M2.

Prezentare AnyLanguageModel: Un API Unificat pentru Modele LLM Locale și Remote pe Platformele Apple
AnyLanguageModel este un pachet Swift inovator care unifică API-urile pentru modelele de limbaj locale și remote pe platformele Apple, simplificând integrarea AI și reducând complexitatea tehnică pentru dezvoltatori.

RapidFire AI: Optimizarea TRL de 20 de ori mai rapidă pentru antrenarea modelelor lingvistice
RapidFire AI revoluționează ajustarea fină a modelelor de limbaj (LLM) prin TRL, oferind o accelerare de până la 20x. Soluția permite rularea concurentă a multiplelor configurații chiar și pe un singur GPU, cu control interactiv în timp real pentru a maximiza eficiența și a reduce timpul de experimentare.

Construirea Deep Research: Cum am atins performanța de ultimă generație (State of the Art)
O analiză detaliată a procesului de dezvoltare a sistemului Deep Research, evidențiind importanța ingineriei contextului, gestionarea eficientă a tokenilor și trecerea de la fluxuri de lucru la agenți autonomi pentru a atinge performanța de ultimă generație.

Batching continuu: De la primele principii la optimizarea inferenței AI
Articolul explorează mecanismele fundamentale ale inferenței în modelele de limbaj de mari dimensiuni, de la atenție și KV caching până la batching-ul continuu, explicând cum aceste tehnici optimizează throughput-ul în scenarii de servire în sarcină ridicată.

Noutăți în llama.cpp: Gestionarea Avansată a Modelelor și Arhitectura Multi-Proces
Echipa llama.cpp introduce un sistem revoluționar de gestionare a modelelor, similar cu Ollama, bazat pe o arhitectură multi-proces. Aceasta asigură stabilitate superioară prin izolarea proceselor și include funcții avansate precum auto-descoperirea modelelor, încărcare la cerere și evacuare inteligentă LRU pentru optimizarea memoriei video.

Differential Transformer V2: O nouă eră în eficiența și stabilitatea modelelor de limbaj de mari dimensiuni
Differential Transformer V2 (DIFF V2) revoluționează arhitectura LLM prin optimizarea eficienței inferenței și eliminarea instabilității numerice specifice versiunii anterioare. Prin dublarea capetelor de interogare și o nouă operație diferențială, modelul depășește constrângerile Softmax, oferind o decodare rapidă fără a necesita nuclee personalizate.