Subiect: #LLM

EAGLE 3.1: Algoritmul de decodare speculativă care repară deriva atenției în inferența modelelor de limbaj
EAGLE 3.1 este un algoritm de decodare speculativă care corectează deriva atenției în inferența modelelor de limbaj, reducând latența cu până la 60% și menținând calitatea textului generat.

MEMO: Un cadru modular pentru antrenarea unui model de memorie dedicat pe cunoștințe noi, fără a modifica parametrii LLM
MEMO este un cadru modular care permite antrenarea unui model de memorie separat de LLM, facilitând actualizarea cunoștințelor fără a modifica parametrii originali. Aceasta reduce costurile, previne pierderea cunoștințelor și permite personalizarea, având potențialul de a revoluționa domeniul AI.

OpenRouter își dublează evaluarea la 1,3 miliarde de dolari într-un singur an
OpenRouter, un startup care oferă un gateway unificat pentru modele AI, a strâns 113 milioane de dolari într-o rundă Seria B, ajungând la o evaluare de 1,3 miliarde de dolari. Creșterea reflectă adoptarea tot mai mare a unei abordări multi-model în industrie.
Together AI lansează open-source OSCAR: un sistem de cuantizare a cache-ului KV pe 2 biți, conștient de atenție, pentru servirea LLM-urilor cu context lung
Together AI a lansat open-source OSCAR, un sistem de cuantizare a cache-ului KV pe 2 biți, care reduce memoria de 8 ori și accelerează decodarea de 3 ori pentru LLM-uri cu contexte lungi, menținând o acuratețe ridicată.
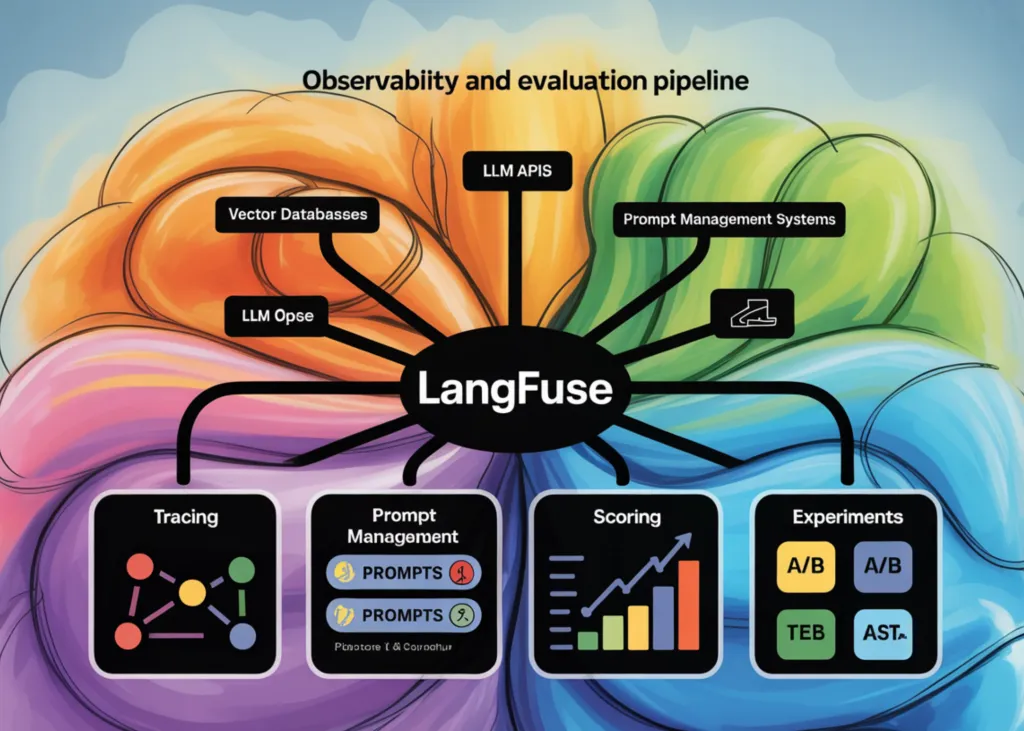
Construiește un Pipeline Complet de Observabilitate și Evaluare cu Langfuse: Urmărire, Gestionarea Prompturilor, Scoruri și Experimente
Descoperă cum să construiești un pipeline complet de observabilitate și evaluare cu Langfuse, incluzând urmărirea, gestionarea prompturilor, scoruri și experimente, pentru a optimiza aplicațiile bazate pe LLM-uri.

Cum redefinește CopilotKit stiva AI agentică în 2026
CopilotKit, un framework open-source pentru agenți AI, revoluționează stiva tehnologică în 2026 prin integrarea seamless cu React, suport pentru multiple LLM-uri și acțiuni personalizabile. Descoperă cum democratizează AI-ul și ce impact are asupra industriei.

Cohere lansează Command A+: Un model MoE de 218B parametri pentru fluxuri de lucru agentice, care rulează pe doar două GPU-uri H100
Cohere lansează Command A+, un model de 218 miliarde de parametri cu arhitectură Mixture of Experts, capabil să ruleze pe doar două GPU-uri H100. Modelul este optimizat pentru fluxuri de lucru agentice, stabilind noi recorduri de performanță și democratizând accesul la AI avansat.

Mese rotunde: Poate AI să învețe să înțeleagă lumea?
O discuție exclusivă între editorii MIT Technology Review explorează cum AI poate trece dincolo de text și învăța să înțeleagă lumea fizică prin modele ale lumii, cu implicații uriașe pentru robotică, mașini autonome și etică.

Cum să comprimi și să evaluezi modelele lingvistice instruite cu FP8, GPTQ și SmoothQuant folosind llmcompressor
Află cum poți comprima modelele lingvistice instruite (instruction-tuned LLMs) folosind FP8, GPTQ și SmoothQuant cu ajutorul bibliotecii llmcompressor. Articolul explică pașii de implementare, rezultatele benchmark-urilor și importanța cuantizării pentru eficiență și accesibilitate.

ArXiv interzice autorii care lasă AI-ul să scrie în locul lor: un an de suspendare pentru lucrări generate neglijent
ArXiv, depozitul deschis de preprinturi științifice, introduce o interdicție de un an pentru autorii care nu verifică rezultatele generate de modelele de limbaj mari (LLM). Măsura vizează lucrările cu dovezi clare de neglijență, cum ar fi referințe halucinate sau comentarii ale AI-ului, și impune ca ulterior trimiterile să fie acceptate de o revistă cu evaluare inter pares.

Zyphra lansează ZAYA1-8B-Diffusion-Preview: primul model de difuzie MoE convertit dintr-un LLM autoregresiv, cu o accelerare de până la 7,7 ori
Zyphra a lansat ZAYA1-8B-Diffusion-Preview, primul model de difuzie MoE convertit dintr-un LLM autoregresiv, care oferă o accelerare de până la 7,7 ori. Articolul explică tehnologia din spate, performanțele și impactul asupra industriei AI.
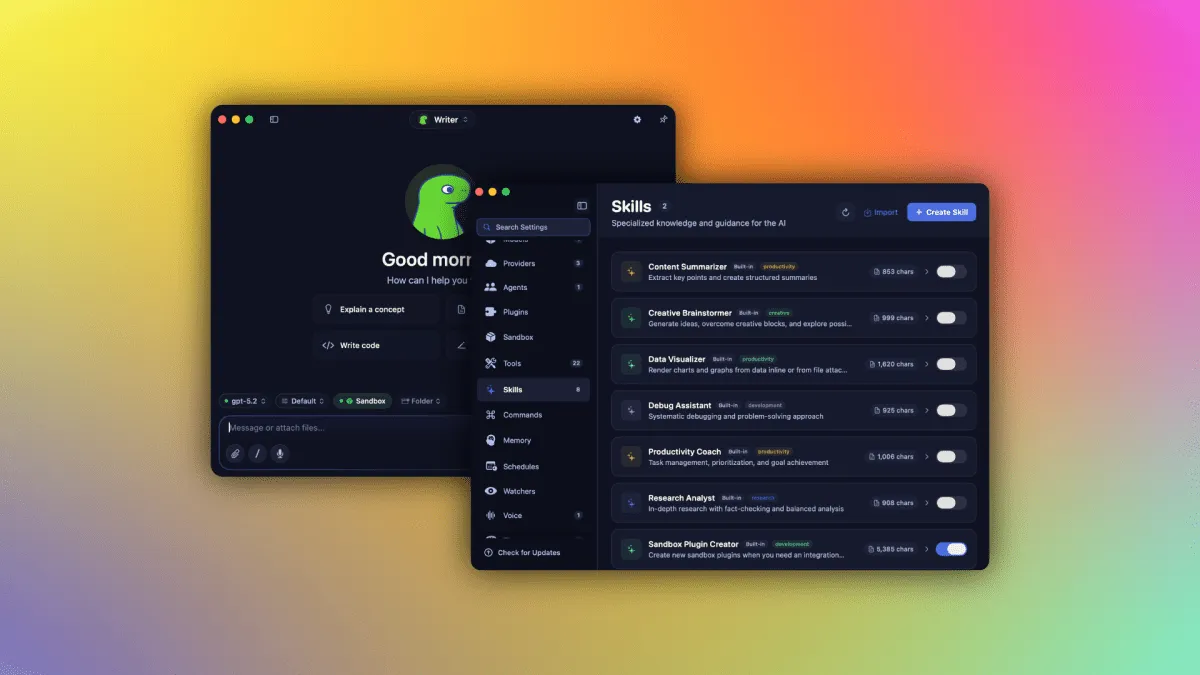
Osaurus: Un server LLM open-source pentru Mac care îmbină inteligența artificială locală cu cea din cloud
Osaurus este un server LLM open-source pentru Mac care permite utilizatorilor să alterneze între modele AI locale și din cloud, păstrând fișierele și instrumentele pe propriul hardware. Oferă o interfață ușor de utilizat, securitate prin sandboxing și suportă peste 20 de pluginuri native. Fondatorii văd potențialul de a reduce dependența de centrele de date AI.