Subiect: #LLM

Cinci îmbunătățiri majore aduse serverelor Gradio MCP: Suport fișiere locale, notificări în timp real și integrare API automatizată
Versiunea Gradio 5.38.0 aduce cinci inovații majore pentru serverele MCP: suport automat pentru încărcarea fișierelor locale, notificări de progres în timp real, transformarea specificațiilor OpenAPI în servere MCP printr-o singură linie de cod, îmbunătățiri ale autentificării prin header-e și posibilitatea personalizării descrierilor instrumentelor.
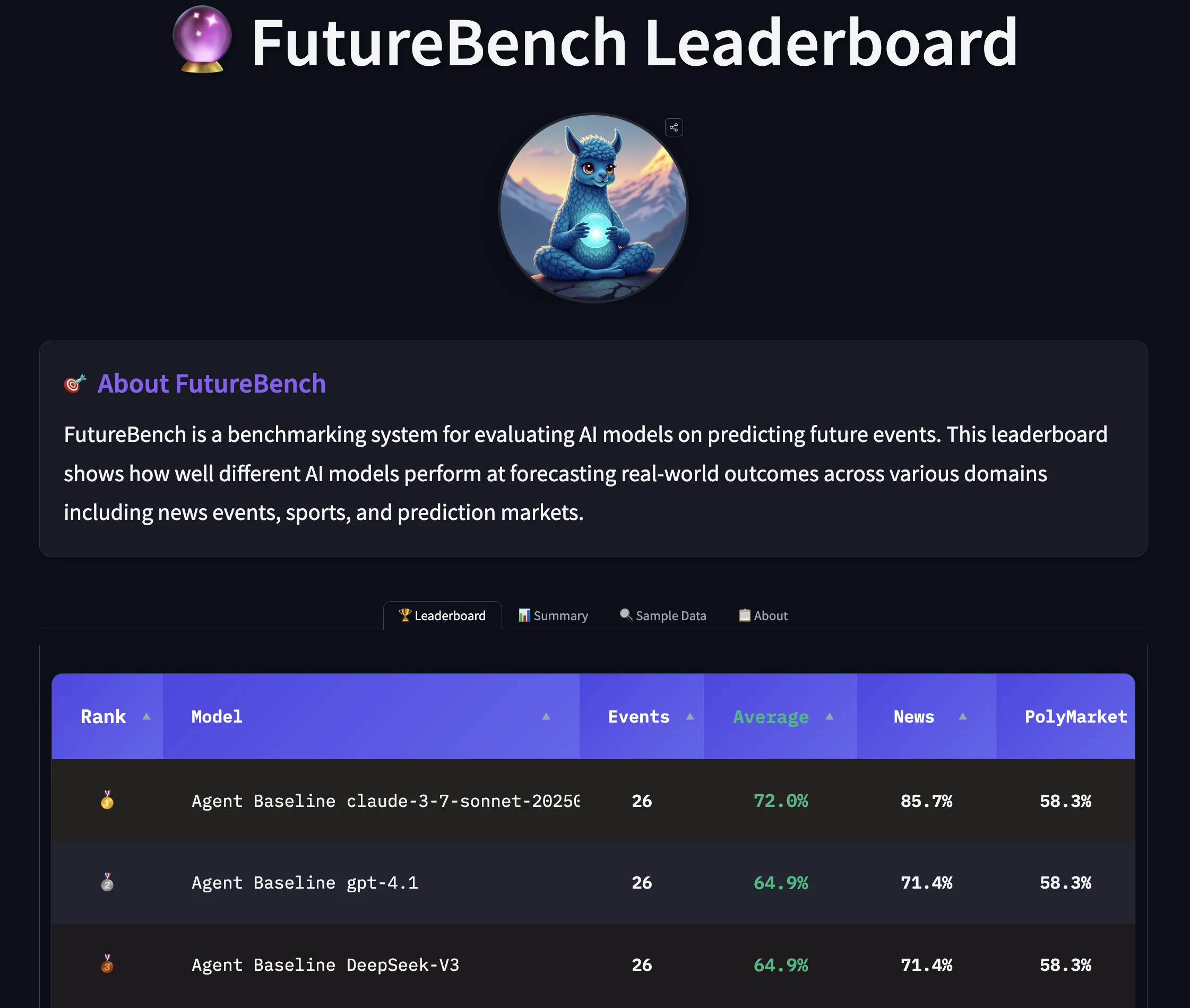
Înapoi în Viitor: Evaluarea Agenților AI în Predicția Evenimentelor Viitoare
Un nou benchmark revoluționar, FutureBench, propune evaluarea agenților AI pe baza capacității lor de a prezice evenimente viitoare, trecând de la testarea memorării faptelor istorice la măsurarea raționamentului complex și a înțelegerii cauzale.

Consilium: Când modelele de limbaj colaborează – O revoluție în inteligența artificială distribuită
Consilium reprezintă o platformă revoluționară care permite multiplelor modele de limbaj mari (LLM) să colaboreze și să discute pentru a atinge consensuri, depășind limitările analizei individuale și validată de cercetări recente care arată că sistemele multi-AI pot atinge 85.5% acuratețe în diagnostic medical comparativ cu doar 20% pentru medicii umani.

Accelerarea implementării modelelor lingvistice mari (LLM) de pe Hugging Face prin NVIDIA NIM: O revoluție în infrastructura AI enterprise
NVIDIA anunță integrarea microserviciilor NIM cu platforma Hugging Face, deblocând accesul rapid la peste 100.000 de modele LLM. Soluția oferă un singur container Docker capabil să optimizeze automat implementarea, detectând arhitectura și selectând backend-ul ideal pentru performanță maximă.

📚 3LM: Un nou punct de referință pentru modelele de limbaj arabe în domeniile STEM și programare
3LM (علم) reprezintă primul benchmark dedicat evaluării modelelor de limbaj arabe în domeniile STEM și generarea de cod, adresând o lacună majoră în peisajul actual al NLP-ului arab prin introducerea a trei seturi de date distincte: întrebări educaționale native, întrebări sintetice de dificultate ridicată și sarcini de programare traduse.

NVIDIA AI-Q și modelele Llama Nemotron: O nouă eră pentru agenții de cercetare open-source
NVIDIA AI-Q Blueprint, un agent de cercetare profund open-source, a atins performanțe de top pe DeepResearch Bench, demonstrând că modelele deschise pot depăși alternativele proprietare. Arhitectura combină modelele Llama 3.3 și Nemotron pentru a oferi raționament complex, transparență totală și implementare flexibilă.
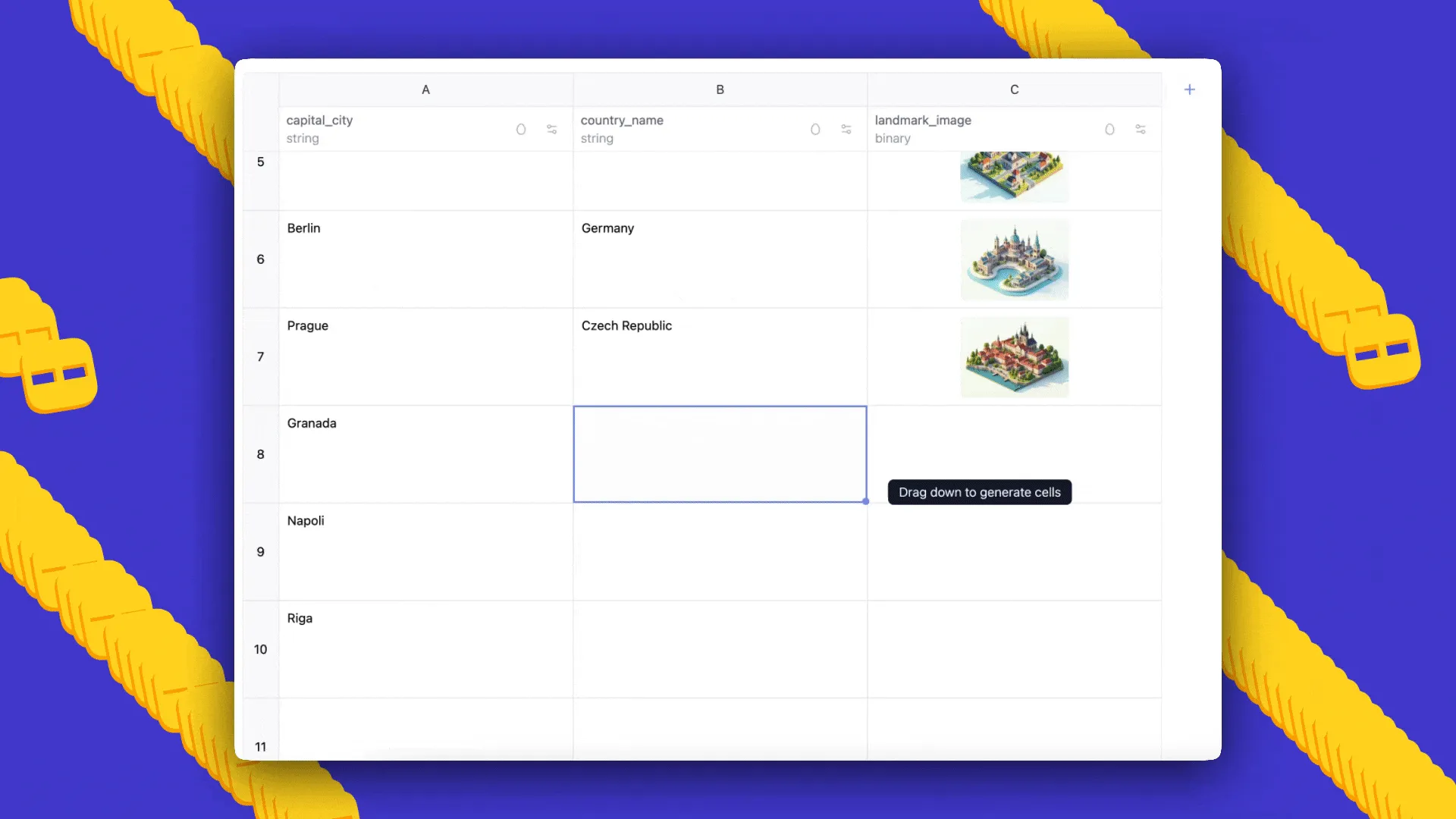
Prezentare AI Sheets: O revoluție în manipularea seturilor de date prin modele AI open-source
Hugging Face lansează AI Sheets, o unealtă revoluționară de tip „no-code” care permite construirea, transformarea și îmbogățirea seturilor de date folosind modele AI open-source, direct dintr-o interfață intuitivă de tip spreadsheet.

🇵🇭 FilBench: Pot modelele de limbaj să înțeleagă și să genereze filipineză?
FilBench este o suită de evaluare lansată în 2025 pentru a testa capacitatea modelelor AI de a înțelege și genera limbaj în filipineză, tagalog și cebuano. Studiul relevă că deși modelele regionale rămân în urma GPT-4, ele oferă o alternativă cost-eficientă și promițătoare pentru comunitățile locale.
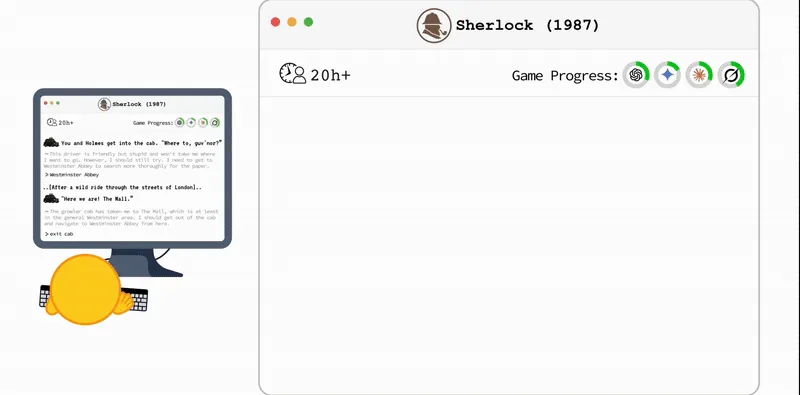
TextQuests: Cât de performante sunt modelele lingvistice mari în jocurile video textuale?
TextQuests este un nou benchmark bazat pe 25 de jocuri clasice de ficțiune interactivă, menit să evalueze capacitatea modelelor lingvistice mari de a raționa pe termen lung și de a învăța prin explorare, relevând dificultăți semnificative în raționamentul spațial și gestionarea contextului extins.

Arm și ExecuTorch 0.7: Democratizarea Inteligenței Artificiale Generative pentru masele largi de utilizatori
Arm revoluționează peisajul tehnologic prin integrarea KleidiAI în ExecuTorch 0.7, aducând capabilități de Inteligență Artificială Generativă, inclusiv modele de limbaj de mari dimensiuni, pe miliarde de dispozitive mobile și edge vechi, democratizând accesul la tehnologia AI.

Kimina-Prover-RL: O nouă eră în demonstrarea automată a teoremelor prin învățare prin întărire
Echipa Kimina lansează kimina-prover-rl, un pipeline open-source de învățare prin întărire pentru demonstrarea teoremelor în Lean 4, care utilizează un paradigmă de raționament structurat și un mecanism inovator de corecție a erorilor, obținând performanțe de top pentru modelele de dimensiuni mici.

Jupyter Agents: Antrenarea modelelor de limbaj pentru raționament bazat pe notebook-uri
Jupyter Agent reprezintă o inovație majoră în antrenarea modelelor de limbaj de mici dimensiuni pentru a raționa și executa cod în medii Jupyter. Proiectul detaliază un pipeline complex de curățare a datelor din Kaggle și fine-tuning, demonstrând cum modelele mici pot deveni agenți eficienți în știința datelor.