Subiect: #vLLM
AI
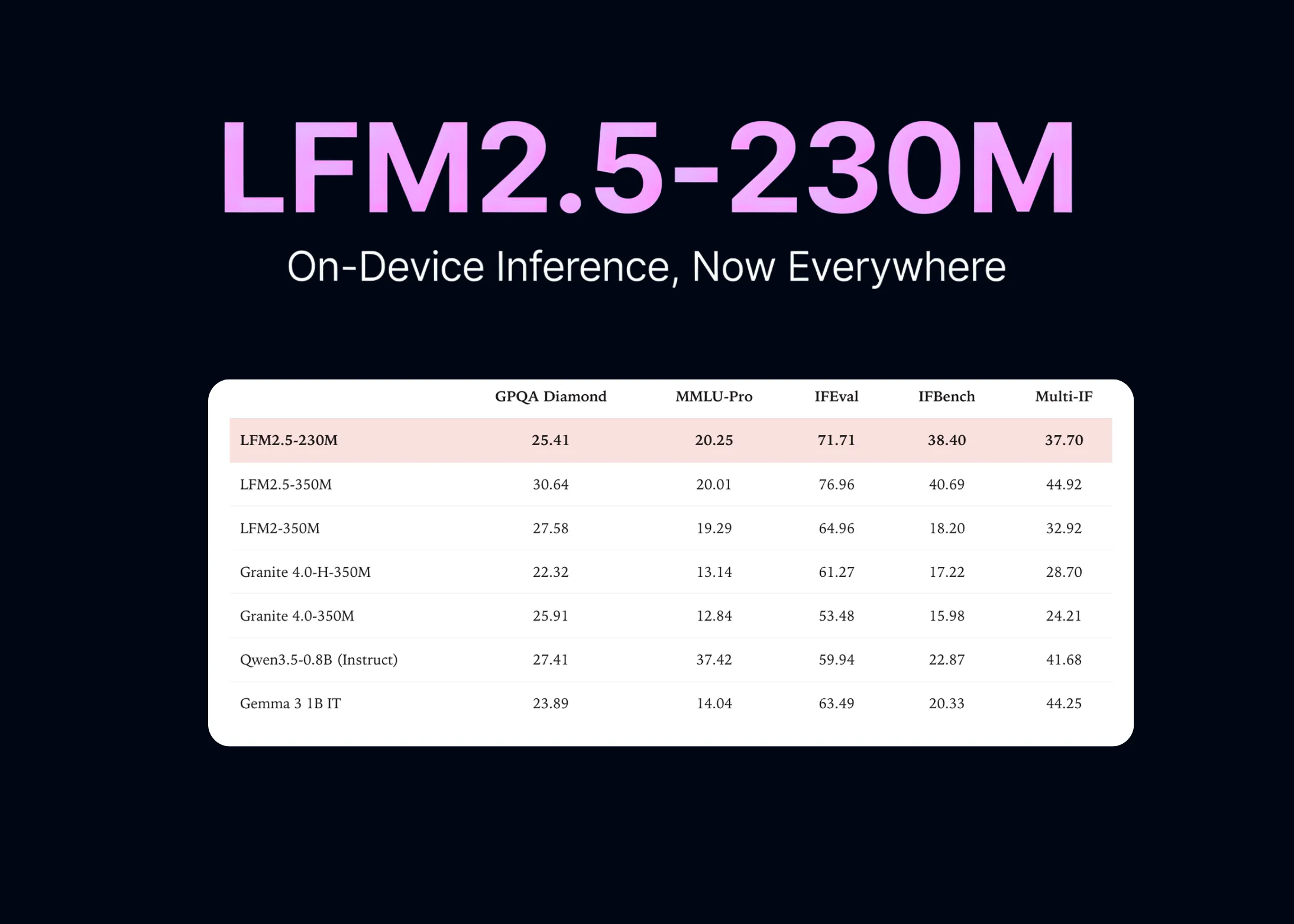
Liquid AI lansează modelul LFM2.5-230M cu suport pentru llama.cpp, MLX, vLLM, SGLang și ONNX – inferență direct pe dispozitiv
Liquid AI lansează modelul LFM2.5-230M cu suport pentru cinci framework-uri de inferență (llama.cpp, MLX, vLLM, SGLang, ONNX), permițând rularea AI-ului direct pe dispozitive locale, fără cloud. Un pas important spre democratizarea inteligenței artificiale.
AI

Accelerarea implementării modelelor lingvistice mari (LLM) de pe Hugging Face prin NVIDIA NIM: O revoluție în infrastructura AI enterprise
NVIDIA anunță integrarea microserviciilor NIM cu platforma Hugging Face, deblocând accesul rapid la peste 100.000 de modele LLM. Soluția oferă un singur container Docker capabil să optimizeze automat implementarea, detectând arhitectura și selectând backend-ul ideal pentru performanță maximă.