Subiect: #OSCAR
AI
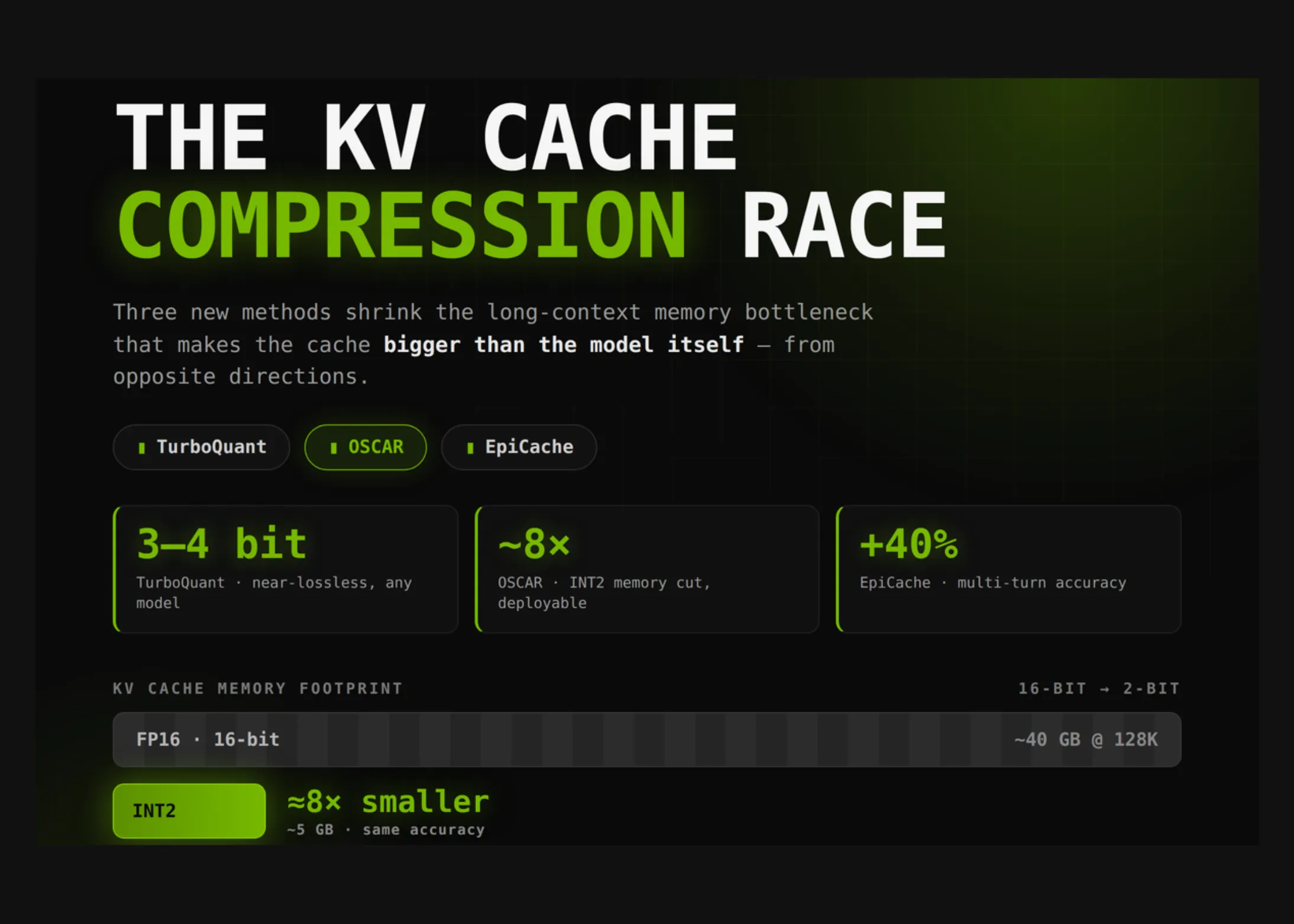
Cursa pentru compresia cache-ului KV: TurboQuant vs OSCAR vs EpiCache
TurboQuant, OSCAR și EpiCache sunt trei tehnologii de compresie a cache-ului KV care revoluționează modul în care rulează modelele de limbaj mari. Fiecare oferă un echilibru diferit între viteză, acuratețe și memorie, deschizând calea către un AI mai accesibil și mai eficient.
Together AI lansează open-source OSCAR: un sistem de cuantizare a cache-ului KV pe 2 biți, conștient de atenție, pentru servirea LLM-urilor cu context lung
Together AI a lansat open-source OSCAR, un sistem de cuantizare a cache-ului KV pe 2 biți, care reduce memoria de 8 ori și accelerează decodarea de 3 ori pentru LLM-uri cu contexte lungi, menținând o acuratețe ridicată.